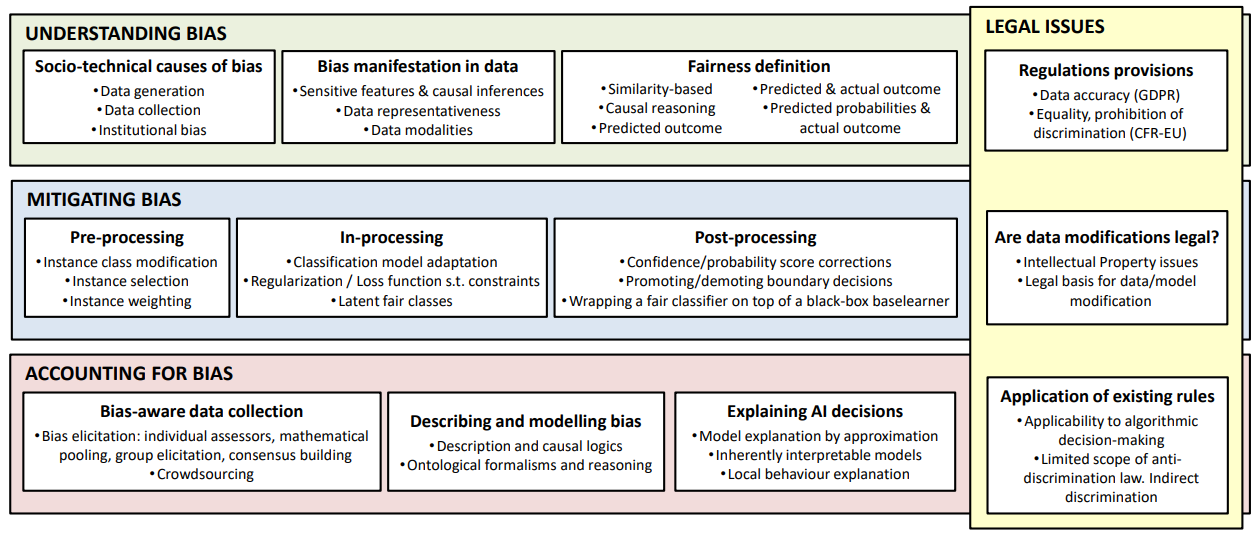
NoBIAS research agenda addresses the whole AI-decision making pipeline with the overall goal of understanding the different sources of bias, detecting them as they manifest and mitigating their effects to the produced results for specific applications. This is made possible by an interdisciplinary approach and a coordinated set of individual projects sharing a global vision. We investigate the challenges by translating them into research objectives, namely, understanding bias in data (O1), mitigating bias in algorithms (O2) and accounting for bias in results (O3). Within each objective, we identify research directions that tackle particular aspects of the problem taking an interdisciplinary approach.
An overview of NoBIAS research agenda is provided below.
 O1. Understanding bias in data
O1. Understanding bias in data
The quality of the data provided as input to AI-decision making processes has a strong influence on the results. Understanding why and how bias is manifested in data is of paramount importance. As part of bias understanding in data, we identify the following challenges with an IRP for each of them:
- Bias-free data generation: How does bias enter into our data/systems?
- Representativeness of data: How biased is the representation of people from data?
- Discovering bias in data: How can we detect bias in data?
- Causality analysis of bias: How do casual relationships affect bias?
- Documenting bias in data: How can we formally represent/model bias?
O2. Mitigating bias in algorithms
AI-decision making systems, enabled nowadays mainly via ML methods, typically optimize some utility measure, exploiting information extracted from data. To account for bias we can improve the bias-related quality of the data or we can introduce extra constraints/costs in the utility measure of the model to “enforce” fairness. The former approach is independent of the algorithm whereas the latter depends on the algorithm per se. In the context of NoBIAS, we tackle both model-independent and model-dependent challenges as well as connecting them with legal issues and contexts, via individual IRPs as follows:
- Model-independent methods: How can we change the data to account for bias?
- Model-dependent methods: How can we change the algorithms to account for bias?
- Legal issues of avoiding bias: How is algorithmic fairness regulated in the national/EU legal systems?
O3. Accounting for bias in results
Results of AI-decision making systems might be biased, even if the data has been corrected for bias and even if the algorithms have been modified to account for bias. One of the reasons is the complex interactions between data and algorithms, especially in case of complex models like deep neural networks. Moreover, new sources of biases are introduced by the interpretation of the results and application context, when continuous model outputs are converted into binary decisions or when concept-drift arises over time. Therefore, an important challenge is to understand the models extracted from data and how certain decisions are taken and evolve over time. It is important to distinguish between accessible algorithms (white models) and inaccessible algorithms (black-box models). We tackle the aforementioned challenges via individual IRPs as follows:
- Explanation in white box models: why has a certain decision for a specific case been taken?
- Dealing with black box models: is a black box model biased?
- Time-evolving models: how can we detect bias and mitigate for bias in temporal data/ data streams?